Apart from listening to metal and writing a review{:target=“_blank”}, I spent my Sunday reading the original LGBM paper and few tutorials on gradient boosting frameworks. In this article, I am writing some notes and my understandings about LGBM.
NOTE: This is post for my future self to look back and review the material. So, this’ll be very unpolished! Consider reading the paper or watching the talks which I mentioned in the References section at the end of this post.
Intro
The title of the original LGBM paper is “LightGBM: A Highly Efficient Gradient Boosting Decision Tree”. This shows that LightGBM is a performance-enhancing version of XGBoost. LGBM gives almost similar accuracy as XGB and is around 15-20 times faster in its training speed.
XGBoost - Pros and Cons
XGBoost is a framework for gradient boosting decision trees and is still active and very popular. But, The use of XGBoost has become less after release of LGBM.
Advantages of XGB
- XGB uses a two-step degree to divide nodes, which is more accurate than other GBMs.
- Different processing details such as Tree Shrinkage and column subsampling.
- The L1/L2 term is added to the loss function to control the complexity and improve the robustness of the model.
- Provides parallel computing capabilities, mainly to find the Gain Infomation of different candidate split points at the tree node.
Disadvantages of XGB
- Uses pre-sorted algorithm, this will consume a lot of memory space [2 * len(data) * no.of_features]
- While segmenting data, each feature needs to be segmented separately during splitting as XGB uses the pre-sorted algorithm for different data features and the sorting order of different features would be different. The number of traversals would be [no.of_features * len(data)]
Therefore, training XGB on large datasets or datasets with many features is time consuming.
LightGBM
LGBM is another gradient boosting framework which was developed by Microsoft in 2016. It immediately became very popular due to its accuracy and high speed processing.
Pros of LGBM
- LightGBM is based on the histogram algorithm instead of the data structure constructed by pre-sorted algorithm.
- LGBM is a gradient boosting decision tree that uses GOSS and EFB.
Gradient Boosting Decision trees usually have two major problems while handling large datasets:
- When dealing with large amounts of data, we will use sampling. While downsampling to reduce the data size, the accuracy falls down because of the change in data distribution.
- Histogram-based algorithms cannot reduce features even for sparse datasets.
Histogram Algorithm
Pre-sorted algorithm usually take lots of space, whereas histogram algorithm’s memory space is relatively very small. The pre-sorted algorithm in XGB needs to save the sorting structure of every feature, the memory size it needs is [2 * len(data) * no.of_feature * 4Bytes]. Histogram algorithm only need to save the discrete bin value and it do not need to save the original feature value, so the occupied memory size is [len(data) * no.of_feature * 1Byte]. In addition, when looking for the corresponding feature histogram of the child node, we only need to construct the feature histogram of one child node, and for the feature histogram of another child node, we can subtract the histogram of the child node just constructed from the histogram of the parent node. The time complexity is compressed to O(k), and k is the number of buckets of histogram.
GOSS - Gradient-based One-Side Sampling
In a method called data downsampling, which is often used to reduce the size of training data, if the distribution of the original data set is downsampled below a frequency that can be restored, the distribution will change, resulting in poor accuracy.
GOSS is a sampling method which down samples the instances on basis of gradients. The gradient boosting decision tree does not accept the sampling technique in AdaBoost, but instead note that gradients can help in this. If the gradient is small, the error is small and it means that the model have already learned enough. One idea that comes to mind here is to discard data with a small gradient, but this has the problem of changing the distribution of the data. Therefore, GOSS adopts the method of random sampling of data with a small gradient while keeping the data with a large gradient.
GOSS in LGBM sets a sampling ratio a to select the ones with large gradients and randomly drop the ones with small gradients from the rest 1-a, by using a ratio b. To compensate for the data loss, LGBM amplifies the small gradient samples when calculating the information gain by multiplying it with the constant .

EFB - Exclusive Feature Bundling
Remember the con of XGB, the traversal takes . If the number of features are reduced, the tree learning will speed up. LGBM uses EFB technique to merge several features together.
High-dimensional data is usually very sparse, which shows that there is a possibility of feature reduction. In addition, the sparseness of high-dimensional data is often exclusive, and it is unlikely that multiple features will take non-zero values at the same time. From such characteristics, it is possible to safely bundle exclusive features into a single feature, and this operation is called the Exclusive Feature Bundle.
There were two questions to think while building such an algorithm:
- How to decide which features are better for fusion?
- How to bundle them together?
Regarding the first point, this problem can be treated as an equivalent to graph coloring problem. Assume features as points (V) in the graph, and the total conflict between features as edges (E) in the graph. Therefore, the problem of finding the merged features and minimizing the number of bundles needs to be done using an approximate greedy algorithm.
- Weight the edges of the graph corresponding to the total number of conflicts (The conflict value used here swas the cos angle between the features) between each feature
- Sort features in descending order
- Check each feature in the sorted list and if conflict < threshold, add it to an existing bundle or else crate a new bundle.
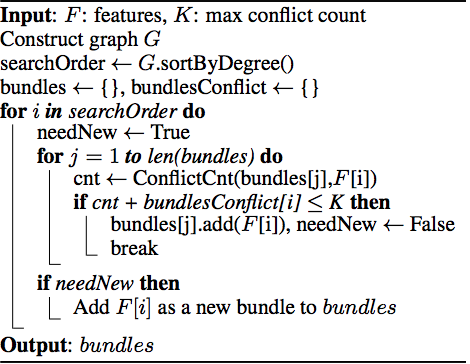
Secondly, for bundling the features - Since the range of features in each bundle is different, we need to rebuild the range of bundle feature after merging. In the first for loop, we record the accumulated totalRange of each feature and the previous features. In the second for loop, a new bin value (F[j]bin[i] + binRanges[j]) is recalculated based on the previous binRanges to ensure that the values between features will not conflict. This is optimized for sparse matrices. Since the previous Greedy Bundling algorithm performs conflict checking on features to ensure that there are as few feature conflicts in the bundle as possible, there will not be too many conflicts between non-zero elements between features.
Now the shape becomes [len(data) * no.of_bundles], where no.of_bundles << no.of_features.

Tree Growth (Leaf-wise)
LightGBM uses Leaf-wise instead of Level-wise for tree growth. This approach is mainly because LightGBM believes that the Level-wise approach will produce some nodes with low information gain and waste computing resources. In fact, in general, Level-wise is still very effective in preventing over-fitting, so everyone prefers to compare it with Leaf-wise. The author believes that Leaf-wise can pursue better accuracy. But this brings about the problem of overfitting, so the author uses max_depth to control its maximum height. The reason is that LightGBM is doing data merging, Histogram Algorithm and GOSS and other operations, which actually have a natural regularization effect, so using Leaf-wise rather than Level-wise to improve accuracy is a very good choice.
Important Parameters in LGBM
num_leaves: the number of leaf nodes to use. (having a large number of leaves will improve accuracy, but will lead to overfitting)max_depth: shallower trees reduce overfittingmax_bin: the maximum number of bins that feature values can be bucketed in (largermax_binincreases accuracy, smallermax_binreduces overfitting)scale_pos_weight: Used for tuning imbalanced data (example weight can be number of negative samples / number of positive samples)feature_fraction: controls the subsampling of features used for training (small fractions reduce overfitting)learning_rate: for better accuracy, use small learning rate and increase number of iterations